Leveraging Sentiment Analysis for Movie Recommendations
Chapter 1: Abstract
The research study is about the “movie recommendation system with sentiment analysis” that had been performed for recommending movies as per the users’ choices. Furthermore, to maintain the choices based on the users’ recommendations in the search lists, this research work was conducted while utilizing Python and sentiment analysis to build the recommendation system. The corresponding research study helped in providing a fruitful recommending model that had been built in the Jupyter Notebook software for implementing the machine learning algorithms. Along with that, python language was used to implement ML techniques to build the model for recognizing the best reviews among all the movies.
In the first chapter of this research study, the abstract and introduction chapter corresponding to the research work were conducted. Moreover, in this chapter, a specific aim and objectives of this dissertation have been elaborated along with the issues of this research work.
In this second chapter, the literature review chapter of this research work has been described appropriately. The concepts of Python and machine learning regarding, ML applications, recommendation systems for suggesting movies, and others regarding this research study have been illustrated to explain the movie recommendation system.
Besides, in the third chapter, the methodology of this research study was enlightened by explaining the steps for conducting the research. Research philosophy, design, strategy, and data collection method have been illustrated specifically.
In the fourth chapter, the results and technical analysis of this research work were analyzed and illustrated for the explanation of the movie recommendation system along with the sentiment analysis approach for recognizing the best movies. The discussion of this research study that had been conducted in the Jupyter Notebook along with HTML has been described briefly with proper explanations.
The last chapter entailed the conclusion of this research work for generating a conclusive statement along with providing a proper future use of this application that helps in the future to suggest the best movies for the users as well.
Get tailored assignment help solutions from Native Assignment Help, a dedicated UK company focused on academic excellence.
Chapter 2: Background
2.1 Introduction
The Recommendation of Movie System with Sentiment Analysis is a type of system that uses movie ratings on IMDb to predict the sentiment of movies. The algorithm takes into account several factors, including how often people have voted on a movie and how positive or negative they are in their votes. It has been discussed that a person can like or dislike a particular film based on their previous voting history. Sentiment Analysis is a process that takes the emotion of an individual and analyzes it. It has compared the emotions of other individuals who have similar emotional characteristics. The analysis provides insight into how others are feeling, their thought processes, and the requirements of users corresponding to their sentiments and recommendations of the choice of the users. This information can be used to determine their needs and desires which in turn helps to better understand them. It has been elaborated that a suitable system has been developed for the mood of users and for recommending popular movies corresponding to their sentiments.
2.2 Background of the study
The background information of the movie recommended by the system helps to recommend the customer’s importance in terms of the information of multiple movies. The movie recommendation system is a technology that can help viewers find the best movies according to their tastes. It can be used as a tool for finding new movies and also as an entertainment tool. If anyone wants to watch something, without knowing where to start then this movie recommendation system will be very useful for them. This kind of application was not present at that time to recommend movies based on search criteria. It will recommend the viewers some good movies based on their tastes and preferences which are already saved in the device. The interfaces of the user’s application are very common and easy to use so that anyone who wants to use it can easily understand how it works without any hassle at all (Wu et al. 2018). Sentiment analysis background is processed for recommended movie system for the work of research in terms of study with the sentiment of movie reviews analysis.
Figure 2.2.1: Analysis of the movie recommendation system as per the recommendations of the users
Behind every review Sentiment analysis can be done based on the development of a concept that tries to understand the emotions and options. Extracted information from the text creates the statistical analysis in terms of machine learning and processing of natural language techniques. Recommendation systems used to review the input inputs of the recommended process can be generated by the process of recommended users for the movie analysis process.
In the past, people have used their own opinions to decide what movie they should watch. However, this method is not very effective because it can be influenced by personal biases and prejudices. Therefore, a new approach was needed that could make recommendations based on objective criteria such as the popularity or quality of movies. As per the view of Reddy et al. (2019), this system uses sentiment analysis to recommend movies according to how people feel about them. The system makes predictions for each user’s preferences and then recommends similar movies based on these predictions. The movie recommendation system with sentiment analysis has been developed to provide users with more accurate recommendations for entertainment purposes. The main objective of this study is to design a movie recommendation system with sentiment analysis. As per the view of Nguyen et al. (2018), the major concern in the current recommendation systems is that they are not able to detect negative emotions or provide recommendations when people are unhappy. This paper proposes a new approach for recommending movies based on the user’s moods and emotions. It proposes an algorithm that can identify the user's mood and then recommend movies accordingly.
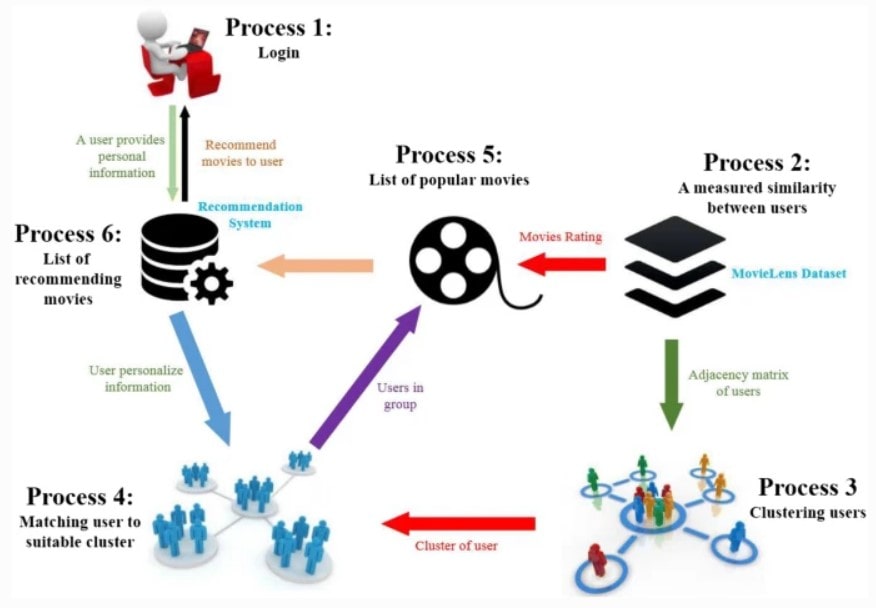
Figure 2.2.2: Flow chart for the recommendation system
The movie recommendation system with sentiment analysis is a machine learning-based method of predicting the user’s preferences for movies. It uses the user's previous ratings and other factors to predict their future rating of a movie. The main objective of this study is to determine if there are any significant differences between the methods used in this research and those used by other researchers, as well as to determine if there are any significant differences between the results obtained using these two different approaches. In addition, it is also determined whether or not there are any significant differences in terms of accuracy when compared with those other studies done on similar subjects. As per the view of Ramzan et al. (2019), this helps find out the movies that are liked by the audience and those who have not watched them yet, so they can watch them later. It also helps in predicting which movie should be recommended next based on their previous choice of movies.
2.3 Aims and objective
Aim
The research aims to recommend movies based on the highest searching movies and best review movies by analyzing the comments or reviews with sentiment analysis.
Objectives
- To find recommended movies based on background research.
- To process sentiment analysis for the recommendation of the movies as per the choice of users.
- Analyzing the movie’s suggestion to check the process of waterfall methodology.
- To develop the recommendation of a movie system based on users by the process of check listing in terms of processing in terms of machine learning as sentiment analysis.
- To suggest movie movie-recommended system as per the user choice has been performed on the Python platform.
2.4 Research questions
- What is the way of gathering the used data based on the search of previous recommendations?
- How to conduct sentiment analysis, and what are the steps in the process?
- Implementation of waterfall methodology to recommended for any kind of movie?
- The development process of the movie to recommend the steps based on the sentiment analysis in terms of an individual recommendation?
- What is the important conclusion to recommend the movie development system?
2.5 Rationale of the Research
What issues have been formed?
The previous recommendation system stated that the movie has been conducted in the absence of sentiment analysis. Most of the research studies including a recommended movie system performed on Python language as machine learning approaches the exact platform to work on with different algorithms. Previously, the recommendation system was there but it did not provide the movies as per the requirements of the users due to the sentiment analysis approach not being implemented in the system.
What issues have been formed next?
The above-mentioned statement is an issue as the sentiment analysis approach can only be implemented using machine learning that has not been processed in the website or any application for which it has become a challenge to the developer. Moreover, recommendation systems have been used in several web applications where a proper sentiment approach was not applied for which the user cannot find the movies as per their choice at the right time.
Why is it an issue now?
The issues have now been raised due to the implementation of the sentiment analysis approach in the recommendations system for which the system is sometimes confused to show the recommended movies based on a search basis or rating basis.
What does the research shed light upon this?
Based on the research, a machine learning process has been created corresponding to the recommendation of movies based on conducting a sentiment analysis to search the previous history in terms of the machine learning process required to shed up light upon the recommended system with a web application for sentiment analysis.
2.6 Significance of the research
The research is significant as it has implications for the management of movies with various categories such as mysterious, romantic, horror, detective, literature, and others. The findings have been useful in improving the quality of searching techniques and helping to identify popular movies corresponding to the choices of the users. This research is significant because it has provided a better understanding of the movie recommendation system with sentiment analysis. It helps to know how people feel about movies and their rating on various aspects such as plot, acting, and music, as well. The current study used data from IMDB (“Internet Movie Database”) which is an “online database system” that contains reports about actors and movies. This study shows that the movie recommendation system with sentiment analysis can be used to recommend movies based on users ‘emotions towards them.
The main reason why movie recommendation systems are useful is that they help users in finding movies that best suit their tastes. As per the view of Aivazoglou et al. (2020), the user can find a list of movies based on his or her preferences and then choose the one that he or she likes most. This way, the user gets to see all his or her favorite movies in one place and hence it saves time as well as money by not having to visit multiple websites for different purposes. This recommendation booking system is the most important part of any movie booking website. It helps the users to manage all the tasks related to the movie booking business. Booking a movie can be done in many ways whereas it is very easy and simple with the online booking system.
2.7 Summary
It has been summarized that the development of the movie recommended system has been updated along with managing the overview of the current situation, identifying potential problems and issues, and suggesting possible solutions. It has been summarized that Python language has been used with sufficient detail to provide readers with enough information to make informed decisions about the future. It should also include action recommendations based on the analysis's findings. This type of document aims to help people understand the research so that the aim and objectives have been discussed. Movie Recommendation System with Sentiment Analysis is a service that helps to find the best movies for user taste. The system uses sentiment analysis to analyze movie reviews and generates recommendations based on these results. It also provides an overview of all movies, which are available in the database.
Chapter 3: Literature Review
3.1 Introduction
Sentiment Analysis is an online application that uses machine learning algorithms to recommend movies according to user moods. The algorithm works by analyzing the user’s past behavior, such as their viewing history, search queries, and other activities they do on the Internet. This data helps to understand what kind of movies will suit viewers’ needs in terms of genre or topic. The Movie Recommendation System with Sentiment Analysis (MSSA) is a novel rating system using sentiment analysis for the prediction of the likelihood of movie success. The MSSA algorithm considers both positive and negative reviews, as well as the number of reviews for each movie.
3.2 Concept of Python
Python is known for the programming language which is very simple and easy to learn. It is a high-level language that can be used for developing application programs. The syntax of Python is also very simple and it does not contain any special characters or symbols. Python was developed by Guido van Rossum in the year 1989 as an extension of ABC. As per the view of Batmazet al. (2019), the concept of Python is to recommend movies based on the ratings of given users. The idea behind this is that the researcher can have a rating system where every user has their own rating and if someone rates a movie highly then it will be recommended to other people who are in a similar mood. This language works on the principle of collaborative filtering which means that we get recommendations from other users who have rated a particular movie highly. Python is a high-level programming language intended to use a general form of syntax. It has a clear syntax and reads like English, so it is easy to learn. Python also has dynamic typing which means variables can be of different types at the same time. This makes it possible to work with several data types in one program, without having to declare them separately.
Python also has a large standard library with useful modules such as NumPy and SciPy, which are used in machine learning algorithms. Among all kinds of programming languages, it is a very easy language to learn and use. Anyone can start with the basics and build on their knowledge as they go along. Another advantage of using Python for movie recommendation is that there are many libraries available, which makes developing applications easier. The general purpose of Python programming language is easy to learn and can be used for many different types of applications. It has an elegant syntax and supports object-oriented programming. The libraries provide the basic building blocks for creating complex predictive models and have been widely adopted by researchers around the world. In addition to these libraries, there are many other open-source packages available on PyPI (the Python Package Index) that can be easily installed using pip (the package manager).
3.3 Requirements of movie recommendation system in the modern era
In the modern era, recommendation systems are used to recommend movies to users. The main objective of these systems is to help people find movies that they would like and enjoy. These systems also make it easier for movie lovers to discover new movies that they might not have known about before. As per the view of Ngoet al. (2020), the most popular kinds of systems recommended include collaborative filtering and based content filtering (CBF). Collaborative Filtering is a method in which users can rate the quality of their favorite films by voting on other users’ ratings. The movie database management module is responsible for storing the movies and their metadata information, such as title, and genre, as well. It also stores the user's preferences and ratings on a particular movie. The data stored in this module can be accessed by other modules to retrieve or update the information about a particular movie or user's preferences and ratings on that particular movie.

Figure 3.3.1: Recommendation System Project
The movie recommendation system, there are many advantages. First of all, it is a very easy way to recommend movies to users. It can be used in any application or website. Secondly, it is a very efficient way to recommend movies to users. Thirdly, it can help the user get more revenue from their site and applications by recommending the best movies for their customers. Fourthly, this method has been proven effective in increasing user engagement on websites and applications as well as improving the conversion rates on these sites and apps by providing better recommendations for users which will increase their satisfaction with the product or service that they have purchased from the site. As per the view of Raghavendra et al. (2018), the scope of the movie recommendation system is to recommend movies based on the user's preferences. The user can specify his/her favorite genre, actors and actresses, and directors, as well. Based on this information, a list of recommended movies will be generated for the user. This system is a great way of getting new customers by the recommendation of suitable movies as per the users’ choices. Moreover, it helps in increasing the sales and revenue of the movies as well. Further, it helps in improving the quality of movies so that the director and cast can understand which movies are recommended more so that the worst movies cannot be created further. They use Google Analytics as their primary source of data collection tool since it provides them with detailed information about visitors’ behavior in terms of their browsing history and interests.
3.4 Different types of machine learning
Machine learning is a branch of computer science that deals with the design of algorithms that can be used to solve problems. Machine learning is based on statistical techniques and involves data mining, pattern recognition, computational complexity theory, and mathematical optimization. As per the view of Forouzandehet al. (2021), it has been applied in a wide range of fields including computer vision, speech recognition, natural language processing, bioinformatics, databases (such as recommendation systems), e-mail spam filtering, robotics (such as autonomous vehicles), data compression or decompression algorithms such as JPEG2000 and MPEG4 Part 10 video coding standards for multimedia applications such as video conferencing and teleconferencing.
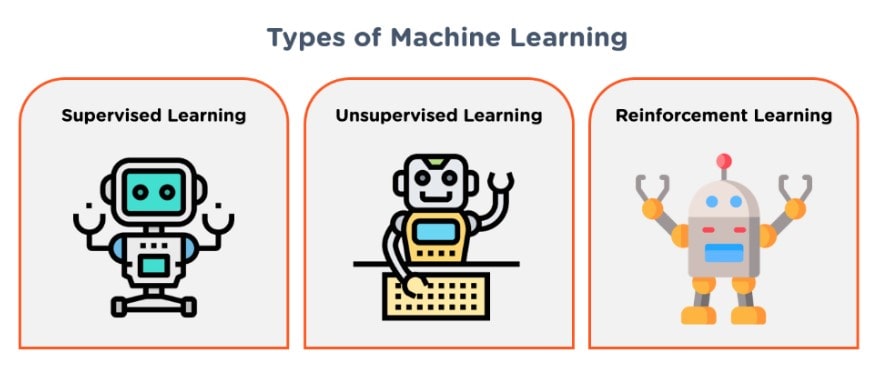
Figure 3.4.1: Types of Machine Learning
As per the view of Yaoet al. (2018), usually three important kinds of machine learning: supervised, reinforcement learning, and unsupervised. Supervision of machine learning involves training a model on labeled examples (such as data that has already been categorized). Supervised machine learning is known as the type of machine learning used to form data to learn about the relationships between input variables and output values. Supervision of learning function can find the function of inputs (x) to outputs (y) variation of maps. This function can be used as an approximation for predicting future outcomes, or it can be used in decision-making. Supervision of machine learning is known as the formation of artificial intelligence in which the computer program can be learned from various examples. In terms of “supervised machine learning”, the goal is to find out what features are important for predicting an outcome and then can be used those features for the prediction of future outcomes. Supervised machine learning requires that the user has labeled data (also called training data) where each example has been assigned a label indicating whether it belongs to one group or another.
Unsupervised machine learning involves training a model on unlabeled examples (such as data that hasn’t been categorized yet). As per the view of Karumuret al. (2018), unsupervised machine learning is a form of machine learning that does not require any labeled data to train the model. The goal of unsupervised machine learning is to discover patterns in unlabeled data, which can then be used for supervised and semi-supervised classification tasks. Unsupervised models are often used for clustering and dimensionality reduction problems, where the user wants to find groups of similar objects or dimensions within an input dataset. Unsupervised machine learning can be used for classification, regression, clustering, and dimensionality reduction. Unsupervised methods aim to find patterns in unlabeled or semi-labeled data without requiring specific user input.
Reinforcement learning is a branch of machine learning that aims to find an optimal policy for an agent. As per the view of Iovine et al. (2020), in other words, it tries to maximize the reward (or minimize the cost) given by a particular action or set of actions to achieve some goal. The main idea behind reinforcement learning is that the researcher can use their knowledge about how humans learn and behave as well as how machines work to design algorithms that can take into account all these factors and optimize their performance. This allows the user not only to train agents with new tasks but also to make them learn from experience without being explicitly programmed.
3.5 Application of sentiment analysis using machine learning
This technique is used in many fields such as marketing, and social media as well. The main aim of this application is to get an idea about what people think and feel by reading their texts. It helps the authority in understanding how people are feeling about certain things or ideas that they have written down in their texts. As per the view of Ansariet al. (2018), sentiment analysis is used for a variety of purposes, including, detecting and analyzing the sentiment in the text (such as tweets) to determine whether it is positive or negative, identifying keywords that are associated with certain emotions, and determining how people feel about products and services by analyzing their social media posts. Application of sentiment analysis using machine learning is the process of analyzing text and extracting information from it. It is a very important step in the development of any application. This can be used to extract information about the user’s feelings and emotions, which help to understand how they feel about something that has been said or written. It assists here for marketing purposes, as well as for other uses such as customer service applications so that reviews of the customers can be extracted for suggesting the best movies. Sentiment analysis is an important part of natural language processing, which is also known as NLP. NLP can be broken down into two main categories, machine translation and natural language understanding (NLU).
Machine translation has been around for decades and uses statistical models to translate one language into another. NLU on the other hand looks at how humans understand words in different languages by analysing the context they are used in. The goal of both types of NLP is to create systems that can understand what people are saying without necessarily having any prior knowledge about them or their backgrounds. Sentiment analysis can be used in many other areas such as social media analytics, customer service, marketing, and more. Sentiment analysis is a technique that leverages the power of natural language processing to identify and extract sentiment from text. It’s essentially a way to understand how people feel about an entity, such as a person or product, by analyzing their words in context.
3.6 Utilization of machine learning in movie recommendation system
Recommendation of a movie system is a complex task. The input to the system is the set of movies that the authority wants to recommend, and the output is a list of recommendations for each user based on their preferences. The problem becomes more challenging when they consider that there are many factors involved in deciding which movie to watch next, genre, actors, directors, and ratings, as well. As per the view of Zhou et al. (2020), they need to consider all these aspects while recommending movies to users so as not to make them disappointed with their recommendation or even frustrate them. The important idea of the project can be used as machine learning algorithms as movie recommendations. The main problem in the current system is that users must choose a movie from a list and then watch it, so they are not able to see new movies. This can be solved with the help of algorithms in machine learning. In addition, they want their users can suggest their favorite movies as per the choice of the spectators and get recommendations on what other people recommend as well. They also want them to be able to create their lists of movies and sort them by different criteria such as genre or rating stars.
A movie recommendation system of the computer program that can be represented as the recommended movies to users based on their tastes and preferences. It is used in many places, such as Netflix, Hulu, iTunes Store, Amazon Video on Demand (VOD), or any other video streaming websites. The main principle of the algorithm is to predict what movies are liked by the user by analyzing their previous viewing history and preference data. As per the view of Fayyaz et al. (2020), the movie recommendation system in machine learning is a type of algorithm that uses the features of movies to predict what movie users will like. It can be used as an alternative to existing methods such as filtering of collaboration and based on content ranking, which are not able to provide accurate predictions for new movies. The main advantage of this method is its ability to recommend new movies that would not have been predicted by other methods.
Recommendation systems are a way to improve the quality of information available on the web. They allow users to find relevant and useful content based on their interests, without having to search for it explicitly. In other words, recommendation engines help people discover new things they might like by showing them what others have liked in the past.
3.7 Benefits and drawbacks of Sentiment analysis in the movie recommendation system
There are so many benefits are there of Sentiment analysis in the movie recommendation system, Sentiment Analysis is a method of assigning a numerical score to a document based on the opinion or attitude expressed in it. It can be used for various purposes like marketing, customer support, and product development as well. As per the view of Kumar et al. (2020), sentiment analysis is a technique used to identify the +ve and -ve words of the text. It helps to understand the mood of the user who has viewed the content. The algorithm will extract positive and negative words from all sentences of a piece of text, then it will show the authority how many times those words have been used in that particular piece of content. This can help to determine whether or not the content is good enough for someone to watch.
The recommendation system is a set of rules that are used to make recommendations. The main objective of the recommendation system is to create a list of recommended items for the user based on his previous purchases, ratings, and other factors. As per the view of Behera et al. (2021), the biggest disadvantage of a recommendation system is that it can be easily gamed. A user could simply write an article on how to make money with Bitcoin, and then get paid in Bitcoins for writing the article. This would result in a very biased view of the currency, and would not give people who don’t use or believe in Bitcoin much of a chance to be heard. Another disadvantage is that there are no guarantees that their recommendations will be used by other users.
As well as there are so many disadvantages are there also, such as The drawback of this method is that it can’t be used for the movie recommendation system. This method cannot be used in the case when there is more than one movie to recommend. The other problem with this approach is that it doesn’t consider the history of a user and his previous ratings. In addition, if they want to use this approach, then they have to create a separate model for each type of movie (such as comedy or action). As per the view of Wang et al. (2018), sentiment analysis is a method of classifying text into positive, negative, or neutral categories. It is used to categorize the content of an article, book review, or movie review. The main reason why the authority uses Sentiment Analysis in the Movie recommendation system is that it helps them understand the emotions expressed by the user while watching a particular movie. This will help them recommend movies based on their emotional content and not just based on their plot and characters.
The main challenge is the amount of data that's required to build a good recommendation system. To get recommendations right, the researcher needs a lot of data. The more data the researcher has, the better their recommendations are going to be. With Facebook and Twitter, they have billions of posts and millions of users every day, so it's not hard for them to generate that kind of volume in terms of content that people can use as inputs into their models.
3.8 Implementation of sentiment analysis for recommending movies
Sentiment analysis is the process of analyzing text to determine whether it has a positive or negative sentiment. As per the view of Singh et al. (2018), the goal of this type of analysis is to identify and understand the sentiments expressed in a particular piece of text, such as reviews or comments on products. For example, if the user were interested in understanding how people felt about an airline's service, then they could analyze their social media posts (such as Facebook) to see what they wrote about their experience with that airline. Sentiment analysis is a method of classifying text into positive, negative, or neutral categories. It uses language and context to determine whether a piece of text is positive, negative, or neutral.
The first step is to identify the emotions contained within the text. The most common emotion categories are anger, sadness, joy, and disgust. Other emotions can be identified by examining how words are used in context. Sentiment analysis is a method of analyzing the sentiment expressed in text. As per the view of Rezaeinia et al. (2019), it can be used to determine whether there is a positive or negative sentiment expressed in a piece of text, and it can also be used to analyze the overall tone of that text.
3.9 Literature Gap
The major drawback of the Movie Recommendation System with Sentiment Analysis is that it does not apply to all movies. This system works by analyzing the sentiment of the text in an article and giving recommendations accordingly.
3.10 Summary
The researcher used sentiment analysis for movie recommendations. Sentiment Analysis is a technology that uses sentiment analysis to determine the sentiment of movie reviews. The system can identify movie reviewers who are more likely to give positive or negative reviews based on their previous ratings and comments. It also analyses the emotional tone of the review, which can help the authority understand why people feel a certain way about movies. Sentiment analysis is a method for the determination of sentiment analysis of the text. It can be used to determine whether a piece of text is positive, negative, or neutral and how strongly it expresses that sentiment.
The algorithm behind this is quite simple, the researcher takes all the words in their document and counts how many times each word appears in the document. Sentiment analysis is the process of identifying and quantifying a document's sentiment, or attitude. It can be used to identify positive or negative opinions about a person, product, brand, event, or topic. For this project work python was used to do sentiment analysis for movie recommendations.
Chapter 4: Contribution of the Methodology
4.1 Introduction
The methodology is the process of planning and conducting research studies. It includes all aspects of a study, such as the design, execution, and analysis of data collection. A researcher will typically use a particular methodology to conduct their study. The methodology is how the researcher collects data, analyses it, and presents the findings. It is a process of how to conduct a research study. The methodology can be categorized into two types: qualitative and quantitative methods. Qualitative methodologies provide more information about people’s thoughts, feelings, and opinions than quantitative methods do. This type of methodology provides a deeper understanding of what people think about an issue or problem at hand because they can tell their stories from their perspective rather than just presenting numbers or facts that may not be accurate. A movie recommendation system with sentiment analysis is a machine learning-based application that can recommend movies to users.
4.2 Research methods
|
Research Philosophy |
As per the view of Madden et al. (2022), realism philosophy is described as a set of beliefs, values, attitudes, and methods that guide research activities about the goals of the research. |
|
Research Approach |
The deductive research approach is a method of scientific investigation in which the researcher makes an assumption about the relationship between two variables and then tests this assumption by making observations or collecting data. |
|
Research Design |
Experimental research design is a research method that involves the systematic manipulation of variables and observation of the outcomes. |
|
Project management approach |
The waterfall model is used to ensure that the project goes through all stages in a planned and orderly manner. |
|
Data Collection Methods |
The secondary data collection method is used for collecting, organizing, and analyzing data that already exists in a database. |
|
Tools and Techniques |
Jupyter Notebook has been used for this project work to design a movie recommendation system using sentiment analysis over the dataset. |
|
Key consideration |
For this project work social, ethical, and legal considerations must be followed. |
4.3 Research Philosophy
Research-based philosophy is a form of academic philosophy that attempts to integrate the best insights from research in various fields with philosophical arguments. It aims at developing new ways of thinking about and doing philosophy. As per the view of Varghese et al. (2019),research-based philosophers seek to develop a more accurate understanding of how the researcher thinks and how they do the work for better efficiency. They aim to improve the quality of life by helping them make better decisions, understand themselves better, and communicate more effectively with others. Their work has been influenced by developments in psychology, sociology, and other social sciences as well as cross-disciplinary studies such as cognitive science or neuroscience. The main objective of this research philosophy is to develop an intelligent system, which can provide recommendations for movies based on human sentiment analysis. In addition, it aims to provide recommendations for movie genres based on the sentiment analysis results. MRS is a research system that has been designed to provide users with recommendations based on their past actions.
On Each Order!
As per the view of Žukauskas et al. (2018), the user manual should be written in a simple language that can be understood by everyone. Furthermore, it should not only explain how to use the system but also provide detailed information on its operation. Researchers need to understand what kind of data will be collected from them and how they contribute to the development process. Research-based philosophy (RBP) is a method of inquiry that explores the nature, origins, and development of philosophical problems.
Justification
In this case, Research philosophy has been selected for this research so that it provides the starting point to the developers for understanding the necessity for developing the movie recommendation system. RBP seeks to understand what researchers have said about philosophical problems and how they have approached them to develop theories and methods for solving those problems. As per the view of Dougherty et al. (2019), the aim is not only to solve those particular problems but also to enrich the understanding of the nature and scope of philosophy itself. The main objective of this research is to find a solution for efficiently recommending movies. This can be done by making use of existing resources such as reviews, ratings, and other factors that are used to make recommendations today.
4.4 Research Approach
The research approach is how the researcher gathers data about the research project. As per the view of Frew et al. (2018), there are two main approaches to conducting a study, such as inductive and deductive methods. These different methods of research can be used for different purposes, but they all have their advantages and disadvantages as well. While the researchers want to find out more about people’s attitudes toward an issue or problem using a qualitative approach would be appropriate as it will allow them to collect deeper insights into people's thoughts and feelings on the matter.
In this case, the researcher was interested in finding out how many people had been affected by a particular problem using a quantitative approach would be better for efficient outcomes. This article is a part of the research project. As per the view of Maher et al. (2018), there are two components are there of the research approach, such as data collection and data analysis. The main goal of this project is to develop a recommendation system for movie recommendations with sentiment analysis. Sentiment analysis is used in many areas, such as marketing and advertising, social media analytics, and web mining, as well. It aims at detecting positive or negative sentiments in text data (such as tweets) or images (such as images on Facebook).
Justification
A deductive research approach has been chosen here for conducting the recommendation system with the help of machine learning for this research. It has helped to find the actual way to the nature of the problem and its complexity, as well as other factors such as resources available for developing the system. The main aim of the research approach is to examine how the viewer makes decisions about watching content, which involves different types of social influence. The secondary objective is to find out whether there are any differences between men and women when they use different forms of social influence on their decisions.
4.5 Research Design
Research design is the process of planning and conducting research. It involves identifying a problem, designing an appropriate study to address that problem, developing a plan for carrying out the study, and monitoring progress during the actual research process. As per the view of Dannels et al. (2018), the design of any research project involves making decisions about how the researcher collects data through interviews or surveys. The researcher has chosen this type of research because it allows the researcher to collect data from individuals who are not under direct observation and also from those who can be observed directly by the researcher. This method is useful for studying large groups of people, especially when the researchers want to know how different variables affect each other.
Research design is the process of planning and executing an experiment. The goal of research design is to evaluate a hypothesis to test it. As per the view of Bloomfield et al. (2019), the research design involves three steps, such as formulating a research question, designing the study, and carrying out the study. The purpose of these steps is to ensure that the results are valid and reliable. It is a systematic approach to the planning and execution of research. It includes all aspects of how the researcher gathers, records, and analyzes data. It is a broad overview of the theoretical framework study’s purpose and focus. For this research work, the researcher uses the movie recommendation system to recommend movies that are similar to the user's preferences. The main idea of this work is to find a way to make a recommender system more effective. For a recommender system to be useful, it needs not only good quality recommendations but also fast and accurate ones. The research design is how the researcher plans to collect data. It includes a statement of their research question and hypotheses, as well as an explanation of how the researcher answers it. The research design also describes the procedures that are used to collect data.
Justification
The experimental research design has been selected to justify choosing a particular population along with choosing a particular setting. Moreover, it has been processed here to generate a rationale for the choice of the study population, setting, and intervention. As per the view of Asenahabi et al. (2019), the researcher must get the exact evaluation for the development of the system while building the system step by step. This may be done by comparing the characteristics of the target group with those that are being studied to determine if there is any difference between them. It may also be used as a way to compare different interventions and find out which one works best. This step helps to identify whether the research design is appropriate for answering the questions that are being asked. The purpose of this section is to provide an overview of what constitutes a good justification and how it can be achieved.
4.6 Data collection method
The data collection method is the process of collecting data. Data collection methods can be divided into two types, such as, active and passive. As per the view of Feng et al. (2021), active data collection methods are those that require human intervention to collect information, such as interviews or questionnaires, passive data collection methods do not require human intervention but rely on natural processes, such as observation or measurement. Data collection is a very important component of any research work. There are two types of that the researcher needs to collect for the research work, one is primary data and the other one is secondary data collection. Data analysis is also a very important step for the analysis of a large data set. Data analysis is the process of using data to answer questions, make decisions, and solve problems. Data cleaning or removing unnecessary data from the dataset is also a part of data analysis. This is a technique used for collecting information from people who have already been selected by some criteria such as age, gender, or location. It can also be used to obtain information about groups of people that have not been previously surveyed but may become relevant in the future. The most common methods are direct observation, structured interviews, and self-report questionnaires. Direct observation involves collecting information by observing the behavior of an individual or group. This method is often used when a researcher needs to observe behavior that may not be easily observed through other means such as surveys or interviews.
In this research, the secondary data collection method has been selected for gathering information on a wide range of issues related to their content at once. Further, this data collection method helps the researcher to analyze the quality of their data. As per the view of Blumenberg et al. (2018), direct observation is the most common form of data collection. It involves a researcher observing behavior unobtrusively and recording it as soon as possible after its occurrence. Observation by proxy, in this method, the researcher observes or monitors another person who is behaving in ways that are like the one being studied. The behaviors observed are recorded by someone else who does not know the subject’s identity or role in the study. The advantages of this approach are that it is relatively easy to administer and collect data from large numbers of people quickly, which means that the researcher can get an accurate picture of how their target audience feels about the content they watch as soon as possible. It also allows the researcher to which may make it easier for the user to see patterns and trends in the results.
4.7 Project management approach
The project management approach is a set of techniques, tools, and methodologies that help project managers to organize their projects. As per the view of Cakmakci et al. (2019), the project management approach helps in planning the work for the project and also helps in keeping track of all activities related to the project. It also guides the achievement of goals within budget limits. This approach involves planning and executing the project in phases. The main goal of this type of project management is to complete the project on time with minimal cost, which means that it has less scope than other approaches. The traditional Project Management Approach (TPA) includes defining objectives and goals for each phase, planning activities, and milestones, managing resources, estimating costs, and communicating with stakeholders.
Waterfall methodologies are often used by large companies that have multiple products and services under development at once. Waterfall methodology requires each phase of the project to be completed before moving on to another phase. As per the view of Thesing et al. (2021), this means that there are no iterations or parallel processes within any given phase, instead, all phases must be completed for the project to move forward. The main advantage of the waterfall methodology is that it is a proven method. It has been used for many years and has proved to be effective in the development process. The approach also helps in keeping track of all the requirements and reducing risks by ensuring that there are no gaps or missing features. This helps in creating a stable product that will last for a long time, as well as reducing costs associated with rework and delays.
The above figure represents the steps for waterfall methodology, it helps to identify each step very clearly. For the proper justification following steps are used, such as,
Requirements
Develop detailed design documents for each phase in the project life cycle. Develop detailed implementation plans, schedules, budgets, and resource allocation plans for each phase in the project life cycle. As per the view of Freitas et al. (2020), estimate the cost to complete each phase of a project based on estimates from previous phases or other sources.
Design
The next step for waterfall modeling is known as the design process for the development process. For the project development, this portion is very important to identify the steps to complete the research work.
Implementation
This step is also very important for the waterfall methodology. In this step, the researcher implements the development as per the requirements of the content for better efficiency of the project.
Verification
In this step, the researcher verifies whether all the criteria of the project are done perfectly or not. If there is any bugs are found in the developed content then these can be removed. So the main purpose of this step is to make sure that the development is done perfectly.
Maintenance and deployment
As per the view of Song et al. (2018), Maintenance very important step for the waterfall methodology, cause for proper maintenance the developed project work can be run properly for a long time as well as the deployment process is also very important.
4.8 Tools and Techniques
Recommendation of movie system has been developed by using the platform of machine learning and HTML for the explanation of movie recommended with the help of algorithms in ML. Further, python programming has been considered for the maintenance of ML algorithms on the platform of Jupyter Notebook and has been created for the process in terms of sentimental analysis for the recommendation of movies as per the viewers and rating comments as per KNN logistic classifier, random forest, and sentimental analysis have been implemented for the prediction outcome based on the dataset so that the best movies have been suggested for the users. This recommendation system has helped to show the recommendations that have been processed by these ML algorithms for the benefit of users while searching best movies. In this case, the system can help to find the movies as per their choices so that while any keyword of a movie is given, the full movie description has been provided to the user.
4.9 Key considerations
The key consideration is that the user understands the risks and benefits of watching the content. As per the view of Tweddle et al. (2018), the user should be able to explain why they have chosen to use an electric toothbrush, what they feel it will achieve, and how they can measure its success. They should also be able to describe the steps taken to ensure that their brushing regimen is effective.
Legal consideration
Legal consideration is a process that ensures the ethical conduct of research. It involves ensuring that all participants are aware of their rights and that they understand how their participation in the study is used. It involves obtaining informed consent from each content before any testing can take place.
Social consideration
Social consideration is the process by which a researcher attempts to obtain permission, or otherwise gain consent, from users who may be affected by the research. It involves an understanding of the nature and context of any potential harm that might result from participation in the study.
Ethical consideration
Ethical considerations are the standards of conduct that govern research. The protection of human subjects and their rights to privacy, confidentiality, and freedom from harm. The assurance that all participants understand the nature of their involvement in a study and the avoidance or minimization of unnecessary discomfort for the subject.
4.10 Summary
For this project work, the researcher has to design a “movie recommendation system”. The research methodology has been discussed for selecting the right approaches for developing the system with machine learning. Hence, the user can easily find out movies corresponding to their taste. For this project work, the researcher needs to collect data for sentiment analysis. Jupyter notebooks are used for the data analysis process. The used dataset uses the data from IMDb and Rotten Tomatoes to predict how much people like or dislike a movie. The important purpose of the project is to help the user in finding good movies according to their taste and preference. It has been summarized that research philosophy has been selected for this project to get the actual informative information while developing the system. Further, the deductive approach and experimental research design have been chosen for getting exact decision-step processes along with necessary experimental data to implement the sentiment analysis in the system. Besides, the secondary collection of data method has helped to find users’ problems and the necessity of a new system in choosing the appropriate movies for the users.
Chapter 5: Evaluation
5.1 Introduction
A Jupyter Notebook is a tool that is used to recommend movies based on the user's preferences. It is an alternative to Netflix or other movie streaming services. The main idea behind this project is to create a web application that recommends movies which are based on the user's taste and preferences, without having any prior knowledge of what kind of movies they like. The movie database component holds all the information about all the movies available online. So, the researcher collects the information of movies as well as the preferences of the user database can form a system of recommendation. The movie recommendation system using Jupyter Notebook is a simple Python script that uses the Movie Lens dataset to recommend movies based on user preferences. According to the selected data set researcher did the data analysis. The goal of this project is to build a model that can predict the ratings given by users for movies on the website and then use these predictions to recommend similar movies to improve user experience.
 use my discount
use my discount
5.2 Analysis
The researcher selected two data sets for this project work and the outcomes of the data analysis process are given below for a better understanding. At first, the researcher needs to import the libraries and it is a very important step because libraries are collections of code written by different programmers to solve specific tasks in Python. As per the view of Wu et al. (2018), these libraries are imported into the Python program to make it more powerful than before. Python libraries are available for data analysis from the beginning of using Python. The Panda’s library is one of the most popular open-source libraries for data analysis and manipulation. It provides a wide range of functions to perform data manipulations such as sorting, filtering, grouping, and joining, as well.
In this step, datasets have been imported and the outcome includes all of the variables in a dataset, as well as their values and any other information required by the statistical software. As per the view of Ahuja et al. (2019), the import process can be performed in ways from a file or an external database. Importing data sets is very important because it allows the researcher to see the data in a spreadsheet format, which makes it easier to visualize and analyze. The outcomes show how the required variables that ed to the content. For this movie recommendation system, the user can easily find out their choices by entering the keywords along with their requirements. This system moves the other content from the home page so that the user can easily find out their required content from the list.
The researcher used two data sets for this project work, so to proceed with the analysis process the researcher needs to merge the data To Roy et al. (2019), data set merge is an advanced feature in Python that helps to combine two or more data sets into one. Data set merge is a very useful tool for data analysis, especially when two different data have been collected from the same sources and it requires merging them. Merge the datasets for data analysis is a process of combining two datasets into one dataset. It helps to reduce the duty and improve the quality of data. As per the view of Singh et al. (2020), it helps to combine multiple files to perform statistical analysis on them. In this process, the researcher does not have a problem with duplicate records and missing values as they are automatically removed from the merged dataset.
In this step, the researcher checks the null values. It shows which variables are missing or have incorrect values, and it can even tell where those problems occur. null values checking is used to check whether a value is null or not. According to the view of Kaushik et al. (2018), null values checking is a technique to check if the data has been entered correctly. It helps in finding mistakes and errors in data analysis. This can be used for both numeric and non-numeric data types. It is a mathematical technique that can be used to measure the degree of positive or negative sentiment towards an object. This technique also helps in identifying the sentiments of a movie and its audience.In addition, it tries to understand whether the audience likes or dislikes any particular movie. It finds out whether people are happy about watching this film or not. When anyone sees movies with high ratings on IMDB then the system knows that they have great reviews from their audiences as well as critics. In such cases, people may want to watch these films again and again because they liked it a lot. In Python, when the researcher is checking the value of a variable, it is possible that the variable may not be assigned any value at all. It has been analyzed that there will be no error message or warning and so it cannot find out what went wrong. It checks whether the variable has any values such as “NA” or not. Moreover, the ISNA function has been used to remove the null values from the overall dataset to project the actual pattern of recommendation.
This step is used for the descriptive analysis of the data set and data understanding. Data understanding is the process of understanding data in terms of its meaning and structure. It helps to understand the set of data is related to each other. As per the view of Jain et al. (2018), descriptive analysis is the process of describing various sets of data in a meaningful way. Descriptive Analysis and Data Understanding are very important in all fields of study. Data is a collection of facts or observations that can be used to make inferences about a particular phenomenon. It includes categorical, qualitative, or, other types of information. The most common form for data is usually tables, charts, and graphs. Descriptive statistics provides the methods to describe various aspects related to data such as frequency distribution, mean, and standard deviation as well. Data analysis involves the process of extracting information from data and presenting it in a meaningful way.
Data understanding and descriptive analysis is the process of extracting useful information from data. As per the view of Bhalse et al. (2021), the main purpose of this process is to understand the data that the researcher has collected and make it more meaningful. It helps in making decisions based on facts rather than opinions or assumptions. Data understanding helps in identifying the problem, which is to be solved by applying data analytics techniques. The descriptive analysis focuses on describing the information that is available in a dataset. It involves analyzing the features or attributes of a particular dataset and finding out some patterns from it.
This step is used for sentiment analysis of selected data. As per the view of Dalton et al. (2018), sentiment analysis is a method of classifying text data based on the sentiment or attitude expressed in the text. Tokenization process in sentiment analysis is a technique used to convert text into tokens. Tokenization is the process of turning raw data into more usable “tokens” or groups of words. Tokens are represented as numbers and can be easily compared, manipulated and processed by computer programs. The main purpose of tokenization is to make the information easier for computers to understand and use in analysis, such as finding patterns in huge datasets.
In sentiment analysis, it has already discussed Sentiment Analysis, which involves extracting a sentence from an article on social media platforms such as Facebook, Twitter and others to find the positive or negative sentiments. As per the view of Banik et al. (2018), these und understanding users think about the content and services and determine how positive or negative they are towards their brand. Sentiment analysis is the process of analyzing text to determine whether it has a positive or negative tone. It is used by the researcher to find out what the user thinks about a particular product, service, or person. In this project, the researcher uses Python for performing sentiment analysis on movie reviews.
Sentiment analysis is used for analyzing how people feel about a particular content. It can be used to determine the overall sentiment of an article or blog post, as well as individual words in the text. According to the view of Jena et al. (2022), this is done by measuring the frequency of positive and negative words within a piece of text. The movie recommendation system has the overall details about the movie to make this system efficient, such as the cast, crew, overview, and genres. Keywords are a very important parameter for a movie recommendation system because the user can also search for the movie by the keywords. It makes the system more attractive and easy to use.
In this step, Conversion of words in sentiment analysis is the process of converting the raw text into a numerical value. There are two types of conversion: 1. Word-to-sentiment 2. Sentiment-to-word. Therefore, Word to Sentiment Conversion. This document describes how to convert words into sentiment values using NLTK’s word2vec and TF-IDF features. The following code converts each word from a list of positive, negative and neutral words (such as, happy, angry and sad) into its corresponding sentiment value: import nltk from sklearn, pre-processing, import StandardScaler, load training and test dataset, vectorizer, bag of words, tokenization and several other steps. The main idea of this project is to search for the user's favorite movies, then use those movies as input to build a model, which predicts new movies that the user might like. Benefits of the Tokenization process in sentiment analysis is that it provides the data points in a structured manner. It can be easily analyzed and used for various purposes such as market research, fraud detection, customer experience, and others. It is beneficial to tokenize text because it allows the sentiment analyzer to capture sentiments from social media posts. Social media content has multiple dimensions like emotions, feelings and attitudes which can be captured by analyzing these different aspects separately. As per the view of Gupta et al. (2020), the movie recommendation system is a kind of machine learning algorithm that can recommend movies. The main idea behind the movie recommendation is to use the information about user’s preferences and other features to predict future movies. In this project work, the researcher needs to know what data needs to be used for making such a prediction. The model is trained by data from other users who have already watched some of their favorite films. The main purpose of this is to make the user watch more interesting movies and reduce the number of times they watch the same movies.
The movies are recommended based on the reviews of the movies previously for which the dataset has been chosen where the titles, movie description, point of discussion of the movie, and others. In addition, the recommended function has been created where the movies can be recommended based on the index value so that the similarity can be checked before applying the sentiment analysis approach. Now, the list, sorted, and lambda are used for categorizing the texts into different formats so that every word can be identified to understand the meaning individually.
5.3 Results
The outcomes for the data understanding and descriptive analysis are given below. As per the view of Saraswat et al. (2020), the main purpose of this process is to understand the characteristics, patterns, and trends in the data. This helps to gain knowledge about the respondents that are studying through surveys. The purpose of this step is to demonstrate the understanding of the data and how it can be used. The descriptive analysis describes the characteristics and patterns of a set of data. Descriptive analysis is a method of data analysis that uses descriptive statistics to describe the characteristics of the content. Descriptive statistics are used to summarize information about content, such as the mean and standard deviation. Descriptive Analysis is an open-source software package for visualizing and analyzing large datasets in Python 3 with interactive plots, statistical summaries, and more than 50 functions for common descriptive statistics such as mean, standard deviation, and frequency distribution charts, as well.
The data understanding process is how data is analyzed and transformed into a form that can be used for decision-making. The data understanding process helps to identify the information needs of this project, analyze data, prepare reports and make decisions based on these analyses. It involves many steps including collecting, organizing, storing, analyzing, and displaying data. Further, this sentiment analysis helps to get the meaning of the sentences from the comments or reviews of the movies. This Analysis is a technique to identify the opinion or feeling of an individual or group concerning the movie recommendation system. The general view about this technology is that it can be used for predicting future trends and also for tracking online conversations, which in turn helps in building a model that can help companies decide on their marketing strategies.
It also helps in creating accurate reports, which are used for decision-making and business processes. As per the view of Awan et al. (2021), the main purpose of this approach is to get more value out of the raw unstructured or semi-structured data by extracting information, cleaning it up, transforming it into new forms, and then analyzing it so that the researcher can derive true.
Sentiment analysis is one of the most important and widely used features in social media marketing. Process of sentiment analysis is an algorithm that can help to identify the emotional state of a text. It works by analyzing the words and phrases that are used in a piece of text, and then categorizing them into different groups. The result is an emotional map where every word has been assigned its own emotional value. In order to understand how process sentiment analysis works, the developer needs to consider some basic concepts about language processing. There are two ways for human beings to communicate: verbal communication and non-verbal communication (such as facial expressions). Verbal communication involves using words as well. Further, tf-idf vectorizer, tokenization, stop words, natural language processing and word text conversion have been implemented to find the meaning of the sentences along with the sentiments of the texts as well.
This can be done by comparing the words in a document with those in other documents that have been tagged as similar. As per the view of Kapoor et al. (2020), the more similar the two are, the higher their similarity score is. The closer they are to each other on this scale, the stronger their relationship is considered to be. The model can then be used to recommend movies to users in a personalized way, which can help them find movies they might like. In this project work, the researcher uses the Jupyter Notebook as the main tool and shows how it works step by step.
Sentiment analysis is a method for determining the text's sentiment. It can be used to ascertain whether a user has a favourable or unfavourable opinion of a piece of content. The chosen data set is subjected to sentiment analysis by the researcher using a Jupyter notebook. The first step in this process is cleaning up the text by removing stop words and punctuation marks. This is to help to get rid of irrelevant information that may not be helpful for the model training. The main benefit of utilizing a Jupyter Notebook is that it enables one to see the findings in a fairly intuitive fashion, but there are many other benefits as well. On text, image, and video data, sentiment analysis is possible to perform. Python does not offer the full range of functionality that the Jupyter Notebook does. Hence, while determining a user likes or dislikes towards a movie, the researcher utilises sentiment analysis in the movie recommendation system. The results presented include precise information about the content summary, genres, keywords, crew, and casing. to make it simple for the user to research a movie using the name of the film. As a result, it is an effective system because it satisfies all criteria for the recommendation system. The user can also search for movies using keywords because they indicate the nature of the content, which makes it simple for them to do so.
For this step, the user also can find out all the related content of the keywords. Hence, they can easily find out their choices because it removes the other content from the home screen and only shows the related content according to the search. The recommendation system defines the content by the keywords that can help the user to find out their choice easily. A movie recommendation system is a program that recommends movies to users based on their tastes. It uses the movie database and user’s profile data to recommend movies. Every digit has been extracted from the sentences to get the meaning and its tokenized values for achieving the actual sentences and its meaning. Further, date, year, numbers are extracted to find the exact values from the features. Therefore, the transform function has been utilized to get the sentiment values with their exact meanings.
It is one of the most accurate features to identify the emotion and sentiment. The data can be used for many other applications such as social media, e-commerce, marketing, customer relationship management and others. There are a lot of keywords that can be extracted from movie ratings like ‘good’ or ‘bad’ or ‘love’ or ‘hate’ or ‘like’ and others. It has been proven by using this feature that there is an increase in sales when people rate a movie positively and vice versa. As per the view of Habib et al. (2020), the algorithm works as follows, such as, for each movie in the database, calculate its average rating for all users who rated it more than once. This is called the “mean” rating and represents how many other people liked this particular movie. Then calculate the user rating by taking their ratings on all movies and averaging them together.
The recommendation system has helped to find the reviews with the help of the recommend function so that the movies can be recommended as per the users’ choices. Along with that, while any keyword of a movie has been given on the function the name of the movie automatically portrayed on the screen. A movie recommendation system helps users to find the best movies according to their tastes. The user can also watch the top-rated movies in different categories. The system suggests some good movies for watching as per the previous history of watching movies. A movie recommendation system is a tool that helps the user to find the right movie for their taste. It also helps the user to discover new movies and get recommendations for them. The best thing about this tool is that it does not require any kind of special knowledge or experience to use it.
5.4 Summary
The movie recommendation system is the process of extracting features from movies and then using such features to recommend other movies. The main idea is to find out the most popular movies and their genres. The researcher uses a user-provided list of favourite movies as well as a database of movie information, which is used for training the model. The movie recommendation system is to provide a user with the best movies that he/she can watch. The system will recommend movies based on the preferences of the user. Movie recommendation systems use machine learning techniques to predict what type of movie a person may like based on his or her past viewing history. The main purpose of the movie recommendation system is to help people find the most appropriate movie according to their tastes and preferences. The system can also be used for finding movies that are similar to a certain movie or even recommending movies based on genre.
It has been summarized that this project work helps to extract information from the users’ comments. It helps in making decisions and finding patterns to recommend the best movies. Data analysis is necessary for this recommendation system that wants to make decisions based on the information they have. For data analysis, the researcher is using the data from IMDB.com to build a recommendation system. The researcher needs to do some pre-processing on these data before feeding them into the machine learning algorithm (Sentiment Analysis).
5.5 Discussion
The researcher used the TMDB 5000 Movie Dataset for the data analysis process. It is a dataset of movie ratings. It contains information about movies including title, year, rating, and genre. It also includes the number of votes received by each movie on the IMDb website as well as a list of all those who have reviewed that particular film. It has been collected by the Internet Movie Database (IMDb) and contains information about over 10 million movies. The data set has been used in many research papers as well as several machine learning applications such as sentiment analysis, topic modeling, and clustering. Sentiment analysis is the process of determining whether a piece of text contains positive, negative, or neutral sentiments. This can be done by using natural language processing techniques to analyze the words and phrases in a document, or through the use of machine learning models that learn how to detect these sentiments automatically. Discussing movies dataset for recommending best movies is a set of movie posters where the movie title and poster are both present.
This dataset is a collection of movies with the most relevant discussions on them. The dataset was collected by scraping the movie discussion forum and storing all of the posts in an SQL database. This data set contains the top 5000 movies from IMDb's database with ratings ranging from 1 to 10. It also includes other meta-data such as genre and year released for each movie in the dataset. This data set has been pre-processed using various methods including, tokenization (removing punctuation characters) and, stemming (removing stop words). The dataset was created by the team at TMDB to help people with their research on movies and television shows from all over the world. The dataset contains two types of data, such as, the first type is the rating information about each movie. This includes the title, year of release, genre, IMDb ID, and several votes it got on IMDb. The second type is the director’s name and their roles in each movie they worked on. These are extracted from Wikipedia pages or from the IMDb page itself if there is no such information available in Wikipedia.
TMDB 5000 Movie Dataset is the largest in the world. It has more than 1 billion ratings, reviews, and comments from over 2 million users. The dataset contains information about movies, actors, actresses, and directors with their social media profiles. Users can rate movies on a scale of 1-5 stars (1 star means bad and 5 stars mean good). They can also write short reviews or comment on movies by writing sentences like “I love this movie” or “This movie sucks!”. It contains more than 1 million unique movies and their associated ratings, reviews, genres, and other metadata. The dataset is available for download from the UCI Machine Learning Repository. The TMDB 50K TV Show Dataset contains metadata on all television programs that have aired in any form since 1950. This dataset can be used to look up information about individual episodes or entire seasons of shows, including their title, air dates, and run times. The main advantage of this system is that it can be used to recommend movies according to the user’s taste.
The other advantages are, it can identify the best movies for a specific genre, also it can recommend new movies based on existing ones. It can suggest new genres and subgenres from existing ones and it can provide recommendations for a particular actor, actress, or director. This recommendation system can be used to recommend movies that are suitable for different age groups to increase the number of viewers of a certain category or genre. The system can recommend movies according to the user's mood, or the movie genre that he/she likes. It can also provide a list of recommended movies for users who don't have time to watch all the movies in one day or those who want some recommendations for their next trip to the cinema hall. The main advantage of a movie recommendation system using sentiment analysis is that it can be used to recommend movies based on the user’s mood.
This is especially useful for recommending movies and other media content that are more subjective in nature, such as music and video games. The user can use the system to quickly find something they like without having to spend time searching through all available options. Sentiment analysis can be used to discover what people think about an event, product, or person. The most common use case is to determine whether someone has written something positive or negative about a company, product, or person. The process starts by identifying the words in the document that are associated with certain emotions.
Sentiment analysis is the process of determining whether a piece of text contains positive, negative, or neutral sentiments. The goal is to determine if there are positive or negative words that can be used to predict the overall sentiment of the content. The researcher selects two CSV files as a data set. Data sets are composed of over 5,000 movies from IMDB. The dataset contains movie review text and the sentiment score for each movie. If the user has a movie with a rating of 3 stars out of 5 then this would be represented as “3” in the dataset. The movie recommendation system is a kind of intelligent computer application that can automatically recommend movies to users. The system uses advanced technologies and algorithms to provide users with the most relevant information about the movies in real time. It also provides recommendations based on user preferences, which are stored in advance by the user through his/her profile. The movie recommendation system can be implemented as an independent software program or as a web-based service provided by a third-party company.
Sentiment analysis is a process of analyzing the texts or comments to determine the sentiment of the users. It has been utilized here for determining the sentiments of the reviews for the movies to recommend best movies to the users. The high accuracy rate of the TMDB 5000 Movie, Dataset is the most comprehensive dataset in the world, with more than 10 million movies and TV shows. It can provide a highly accurate sentiment analysis result for every movie or TV show in this dataset. As well as for the flexible configuration it can choose to use the pre-trained models or train its custom model on top of it by using API. Sentiment Analysis is an interesting technique that tries to understand what people think about different topics or objects by analyzing their writing style and language patterns about these topics.
The implementation of sentiment analysis using TMDB 5000 Movie Dataset is a supervised learning problem. The dataset contains the ratings of movies as well as movie posters and trailers. The implementation of sentiment analysis using IMDB the Movie Dataset is a supervised learning problem. The dataset contains the ratings of movies as well as their posters and trailers. TMDB 5000 Movie Dataset is a collection of more than 500,000 movies from the Internet Movie Database (IMDb), which has been carefully curated to include only those films that have already been released in theatres. This dataset is useful for research into how people consume media content on various devices or platforms. The data is available in CSV format. TMDB 5000 Movie Dataset is a dataset that contains information about movies. The dataset includes information such as the name, year of release and genre of movies. This data can be used for many purposes including movie recommendation engines, movie search engines, as well.
Sentiment analysis is a technique used to determine the overall sentiment of a piece of text. The goal is to identify and quantify the positive, negative or neutral words in a text so that the researcher can understand their meaning. This is done by analyzing the frequency of occurrence of each word within the document. Sentiment analysis is a technique used to analyze the sentiment of text. It can be used to detect positive, negative and neutral words in a sentence. The word is classified as positive if there are more occurrences of that word than negative or neutral words in the same sentence. Sentiment analysis uses an algorithm called TF-IDF (Term Frequency – Inverse Document Frequency) which calculates how much each term contributes to the overall score for a given document/sentence. The goal of this project was to determine if the movie dataset had any bias towards certain genres or topics.
Data of movie reviews is collected from IMDB.com website, which has more than 200 million movies in its database. The data of each review is stored as a single text file with the following format, Review ID, Title, Director and Genre. The user can search for a movie through the web browser and then it will show all movies that are similar to the searched one and also provide ratings of each movie based on its popularity. After finding a suitable movie, the user can rate it by clicking the “Rate” button, which is shown on every page and also provide rating details like title, stars, release date of the movies as well. Implementation process of movie recommendation system using sentiment analysis is as follows, data collection and pre-processing, vectorizer, tokenization, stop words, sequential model and predictions are very important processes that has to collect the data from different sources like IMDB, and Rotten Tomatoes as well.
Chapter 6: Conclusion
6.1 Conclusion
This project work represents a movie recommendation system using sentiment analysis over a selected dataset. The researcher used Jupiter Notebook for the data analysis process with Python. The overall process follows all the methods properly which can make the system more accurate and usable for the user. The main purpose of this project is to make a system that can suggest accurate content to the user as per their taste. The purpose of a movie recommendation system is to provide users with the most relevant information about movies and videos. In other words, it should be able to recommend a video based on the user’s interests. So, when the user watches a movie or video online, the system can suggest to them more similar ones that they might like. The researcher used the code for the above purpose and to make the system more efficient with the upgraded features.
There are so many advantages are there that the user can found during using this website, such as, can recommend movies according to the user’s taste, and also can conveniently show the recommended movies. Also, the system can analyze user tastes, so it does not recommend movies that are disliked by users. It provides the user with a list of movies that are most suitable for their taste and preferences. They can also find out some other useful information about a particular movie, such as its genre, rating, or release date as well. As well as there are some disadvantages also, such as the major disadvantage is that it doesn’t provide any kind of reviews about a particular movie so far. But the overall system is very uses full and help full for the user. This method has been used in many applications including Netflix, IMDB, and Amazon. In this project work, the researcher is cover how to build an effective movie recommendation system using sentiment analysis. A proper methodology and literature review of the project work are given. As well as the analysis part used for the proper description of the technical work of the movie recommendation system for the proper understanding.
6.2 Linking with Objectives
This section is used for linking up with the objectives of the project work. This can provewhether this project work was done as per the objectives or not. So this section discussed abo objectives and how this work met the requirements.
Linking with Objective 1
As per the first objective, this objective has been linked with Chapter 1 (1.2) and Chapter 2 (2.3) to describe the background and requirements of this approach.In this project work, the researcher make the system as per the requirements, and it is shown in the analysis part that when the user enters a movie name then he or she also can find out the genres, an overview of the movie as well as the popularity and budget of the movie are also shown on the recommendation system. So that the user can easily find out the background of the movie that can describe the movie more. As per the first objective, the recommendation system has features that can show the background of the movie, and this requirement fulfilled.
Linking with Objective 2
The second objective has been linked with Chapter 2 (2.6 and 2.8) and Chapter 3 (3.7) to discuss the implementation process for the movie recommendation system. This is also fulfilled by the researcher on this project work because this recommendation system recommends movies to the user as per the past watching history and search history of the user. So the recommended movie must be related to history. The researcher used a sentiment analysis process for this movie recommendation system and sentiment analysis recommends the movie after analyzing the past watching or search history of the user. So that this movie recommendation system also met the second objectives requirements.
Linking with Objective 3
The third objective has been linked with Chapter 3 (3.7) to elaborate the approach of waterfall methodology to elaborate this research step by step. This is also fulfilled by the researcher for this project work. For this movie recommendation system, the researcher used the waterfall methodology model and the details about this process are given in the above methodology section. This recommendation system used the waterfall methodology for suggesting the movies to the user as per the requirement. Hence, the recommendation system also fulfills the third objective of this project work.
Linking with Objective 4
This objective has been linked with Chapter 4 for developing the “movie recommendation system” with the help of machine learning approach. For this project work, the researcher used Jupyter Notebook to design the “movie recommendation system” with Python and the “movie recommendation” as per the user preference researcher used a sentiment analysis process to make this system more accurate. The movie recommendation system recommends the movie to the user as per their history, and for this recommendation, sentiment analysis is done over the past data of the user. A clear overview of the sentiment analysis is given in the analysis section. Therefore, it clearly shows that this recommendation system met the requirements of the fourth objective.
Linking with Objective 5
According to the fifth objective the researcher needs to suggest the conclusion for the “movie recommendation system” for which “python language” has been used. It has been linked with chapter 2 (2.2) and 5 (5.1) to elaborate necessity of Python in suggesting the “movie recommendation system” with help of “machine learning” approaches.
6.3 Recommendation
The basic idea of this “movie recommendation system” is to use the user’s previous ratings and their current mood as features. The algorithm then tries to predict what kind of movie they would like next based on these features. The movie recommendation system uses sentiment analysis to identify the sentiment of a user's text. The system can make recommendations based on the positive and negative sentiments in the text. If a user posts a comment positively, then the system recommends movies with similar positive sentiments. As per the view of Deldjoo et al. (2018), “text mining” is the methos of extracting information from unstructured text documents. This can be done by using various techniques such as NLP, which stands for natural language processing. Sentiment analysis is a technique that uses machine learning to extract sentiment from text and present it understandably. It does this by classifying words as positive or negative based on their context and meaning. The movie recommendation system described above could use sentiment analysis to classify each word into its respective category (positive or negative).
Latent semantic analysis is a machine learning technique that can be used to extract the latent semantics of text. It is based on statistical techniques such as principal component analysis and factor analysis. The output of LSA is a set of vectors, where each vector represents one word or phrase in the corpus. Latent Semantic Analysis (LSA) is one of the most popular methods for document classification. LSA has been applied to many different fields such as biology, medicine, social sciences, and computer science. Each vector contains information about how similar it is to other words or phrases in the same group. As per the view of Ansari et al. (2018), this technique has been applied successfully for many NLP tasks, including sentiment analysis. So for the movie recommendation system, the researcher can also use these techniques for better efficiency. Word embedding is a way to represent words in vectors. Such vectors are called word embeddings and the representation of words as vectors is called word embedding. Word embeddings can be used for many applications, such as language modelling, machine translation, information retrieval, or content-based image retrieval. For this project, the researcher can use word embeddings to represent movie reviews to predict the sentiment of a review. The recommendation system need to categorized such as horror, romantic, detective and other categories to find the exact movie based on the search results of the users. This can be done by analyzing the words that are used in a text or video and finding out their meaning, which then can be used as input for a recommender system for which yolo machine learning model can be used.
6.4 Limitations of the research
There are some limitations are there of movie recommendation system are there, such as the limitation of the movie recommendation system using sentiment analysis that doesn't work well with movies that have a negative or positive tone. As per the view of Wang et al. (2019), if the user watches a movie about drug addiction, the system is thereby going to recommend another movie about drug addiction. The same goes for other types of movies like horror or action films. This can be fixed by creating a separate classifier for each type of genre and then combining them in an ensemble method. The limitation of the movie recommendation system is that it cannot recommend movies that are not available in the library. The user can only see the movies which are already present in the library and also he/she cannot change any of these movies. This is because a movie has to be present in all libraries before it can be recommended.
Sentiment analysis can only identify positive or negative emotions. But it cannot determine the intensity of emotions, which means that a high level of positivity may not necessarily be considered as good and vice versa. As per the view of Deldjoo et al. (2021), the limitation of sentiment analysis is that it only works on text. It cannot be applied to images, videos, or other forms of media. The sentiment analysis tool can also not identify the emotion behind a particular word or phrase, but it can help to determine if there is any positive or negative connotation associated with a particular word. The limitation of the “movie recommendation system” using sentiment analysis is that it cannot recommend a movie based on the user’s preferences. The other limitation is that it can only recommend movies with positive sentiments. Therefore, this method is not suitable for recommending movies that have been released in recent years or those which do not have an existing fan base. The limitation of the movie recommendation system using sentiment analysis is that it cannot be applied to all kinds of movies. It can only recommend a movie if the user has watched the same kind of movie before, and they are likely to enjoy it.
6.5 Future Scope
The future scope of the “movie recommendation system” is to provide a new way for users to get the latest movies. The user can access the website and see all the latest movies that are recommended by the algorithm. The user will be able to choose from different categories such as action, drama, comedy, and so on. As per the view of Li et al. (2018), the user will also be able to download these movies in various formats like mp4, and Mkv as well. These movies can be played via any media player or downloaded on a mobile device and watched later their TV sets or laptops. The users can get their favorite movies from the server and can conveniently watch them. The future scope of a movie recommendation system using sentiment analysis is to provide a better and more accurate movie recommendation system. The movie recommendation system uses sentiment analysis to predict whether it will like a particular movie, based on the user’s previous preferences. The user can also see these recommendations on different social media platforms like “Facebook”, “Twitter”, and “Google Plus”. These systems use word embeddings to make predictions about how likely an individual user would be to like or dislike a particular movie based on their past behavior and preferences.
The future scope of this project is to use the data from social media sites and other sources like IMDB, Rotten Tomatoes, and others. This will help in recommending movies according to the user’s taste. The future scope of this project is also in terms of the prediction of movies as a user would like or not to be based on the previous movie recommendations made by them. The future scope of a “movie recommendation system” using “sentiment analysis” is to find out the best movies for a person. As per the view of Deldjoo et al. (2019), the idea behind this is that if the user can recommend the best movies for a person, then he/she will have more chances of watching those movies and thus enjoy them. This will also help in making the people to watch other good movies, which are not recommended by the system they are favorable to. Hence, several approaches can be implemented in this project work and make this project more efficient and effective.
Reference List
Ahuja, R., Solanki, A. and Nayyar, A., 2019, January. A movie recommender system using K-Means clustering and K-Nearest Neighbor. In 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence) (pp. 263-268). IEEE.
Aivazoglou, M., Roussos, A.O., Margaris, D., Vassilakis, C., Ioannidis, S., Polakis, J. and Spiliotopoulos, D., 2020. A fine-grained social network recommender system. Social Network Analysis and Mining, 10(1), pp.1-18.
Ansari, A., Li, Y. and Zhang, J.Z., 2018. Probabilistic topic model for hybrid recommender systems: A stochastic variational Bayesian approach. Marketing Science, 37(6), pp.987-1008.
Ansari, A., Li, Y. and Zhang, J.Z., 2018. Probabilistic topic model for hybrid recommender systems: A stochastic variational Bayesian approach. Marketing Science, 37(6), pp.987-1008.
Ansari, A., Li, Y. and Zhang, J.Z., 2018. Probabilistic topic model for hybrid recommender systems: A stochastic variational Bayesian approach. Marketing Science, 37(6), pp.987-1008.
Asenahabi, B.M., 2019. Basics of research design: A guide to selecting appropriate research design. International Journal of Contemporary Applied Researches, 6(5), pp.76-89.
Awan, M.J., Khan, R.A., Nobanee, H., Yasin, A., Anwar, S.M., Naseem, U. and Singh, V.P., 2021. A recommendation engine for predicting movie ratings using a big data approach. Electronics, 10(10), p.1215.
Banik, R., 2018. Hands-on recommendation systems with Python: start building powerful and personalized, recommendation engines with Python. Packt Publishing Ltd.
Batmaz, Z., Yurekli, A., Bilge, A. and Kaleli, C., 2019. A review on deep learning for recommender systems: challenges and remedies. Artificial Intelligence Review, 52(1), pp.1-37.
Behera, R.K., Jena, M., Rath, S.K. and Misra, S., 2021. Co-LSTM: Convolutional LSTM model for sentiment analysis in social big data. Information Processing & Management, 58(1), p.102435.
Bhalse, N. and Thakur, R., 2021. Algorithm for movie recommendation system using collaborative filtering. Materials Today: Proceedings.
Bloomfield, J. and Fisher, M.J., 2019. Quantitative research design. Journal of the Australasian Rehabilitation Nurses Association, 22(2), pp.27-30.
Blumenberg, C. and Barros, A.J., 2018. Response rate differences between web and alternative data collection methods for public health research: a systematic review of the literature. International Journal of Public Health, 63(6), pp.765-773.
Cakmakci, M., 2019, May. Interaction in project management approach within industry 4.0. In International Scientific-Technical Conference MANUFACTURING (pp. 176-189). Springer, Cham.
Dalton, J., Ajayi, V. and Main, R., 2018, June. Vote goat: Conversational movie recommendation. In The 41st InternationalACM sigir conference on research & development in information retrieval (pp. 1285-1288).
Dannels, S.A., 2018. Research design. In The Reviewer’s guide to Quantitative Methods in the Social Sciences (pp. 402-416). Routledge.
Deldjoo, Y., Bellogin, A. and Di Noia, T., 2021. Explaining recommender systems fairness and accuracy through the lens of data characteristics. Information Processing & Management, 58(5), p.102662.
Deldjoo, Y., Dacrema, M.F., Constantin, M.G., Eghbal-Zadeh, H., Cereda, S., Schedl, M., Ionescu, B. and Cremonesi, P., 2019. Movie genome: alleviating new item cold start in movie recommendation. User Modeling and User-Adapted Interaction, 29(2), pp.291-343.
Deldjoo, Y., Schedl, M., Cremonesi, P., Pasi, G. and Cremonesi, P., 2018. Content-based multimedia recommendation systems: definition and application domains.
Dougherty, M.R., Silva, L.R. and Grand, J.A., 2019. Making research evaluation more transparent: Aligning research philosophy, institutional values, and reporting. Perspectives on Psychological Science, 14(3), pp.361-375.
Fayyaz, Z., Ebrahimian, M., Nawara, D., Ibrahim, A. and Kashef, R., 2020. Recommendation systems: Algorithms, challenges, metrics, and business opportunities. applied sciences, 10(21), p.7748.
Feng, Y., Duives, D., Daamen, W. and Hoogendoorn, S., 2021. Data collection methods for studying pedestrian behavior: A systematic review. Building and Environment, 187, p.107329.
Forouzandeh, S., Berahmand, K. and Rostami, M., 2021. Presentation of a recommender system with ensemble learning and graph embedding: a case on MovieLens. Multimedia Tools and Applications, 80(5), pp.7805-7832.
Freitas, F., Silva, F.J., Campilho, R.D.S.G., Pimentel, C. and Godina, R., 2020. Development of a suitable project management approach for projects with parallel planning and execution. Procedia Manufacturing, 51, pp.1544-1550.
Frew, A., Weston, L.A., Reynolds, O.L. and Gurr, G.M., 2018. The role of silicon in plant biology: a paradigm shift in research approach. Annals of Botany, 121(7), pp.1265-1273.
Gupta, M., Thakkar, A., Gupta, V., and Rathore, D.P.S., 2020, July. A movie recommender system using collaborative filtering. In 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC) (pp. 415-420). IEEE.
Habib, J., Zhang, S. and Balog, K., 2020, October. Iai MovieBot: A conversational movie recommender system. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (pp. 3405-3408).
Iovine, A., Narducci, F. and Semeraro, G., 2020. Conversational Recommender Systems and natural language:: A study through the ConveRSE framework. Decision Support Systems, 131, p.113250.
Iovine, A., Narducci, F. and Semeraro, G., 2020. Conversational Recommender Systems and natural language:: A study through the ConveRSE framework. Decision Support Systems, 131, p.113250.
Jain, K.N., Kumar, V., Kumar, P. and Choudhury, T., 2018. Movie recommendation system: hybrid information filtering system. In Intelligent Computing and Information and Communication (pp. 677-686). Springer, Singapore.
Jena, K.K., Bhoi, S.K., Mallick, C., Jena, S.R., Kumar, R., Long, H.V. and Son, N.T.K., 2022. Neural model-based collaborative filtering for movie recommendation system. International Journal of Information Technology, pp.1-11.
Kapoor, N., Vishal, S. and Krishnaveni, K.S., 2020, June. Movie recommendation system using NLP tools. In 2020 5th International Conference on Communication and Electronics Systems (ICCES) (pp. 883-888). IEEE.
Karumur, R.P., Nguyen, T.T. and Konstan, J.A., 2018. Personality, user preferences and behavior in recommender systems. Information Systems Frontiers, 20(6), pp.1241-1265.
Karumur, R.P., Nguyen, T.T. and Konstan, J.A., 2018. Personality, user preferences and behavior in recommender systems. Information Systems Frontiers, 20(6), pp.1241-1265.
Kaushik, A., Gupta, S. and Bhatia, M., 2018. A movie recommendation. A system using Neural Networks. International Journal of Advance Research, Ideas, and Innovations in Technology, 4(2), pp.425-430.
Kumar, S., Gahalawat, M., Roy, P.P., Dogra, D.P. and Kim, B.G., 2020. Exploring the impact of age and gender on sentiment analysis using machine learning. Electronics, 9(2), p.374.
Li, J., Xu, W., Wan, W. and Sun, J., 2018. Movie recommendationsare based on bridging movie features and user interest. Journal of computational science, 26, pp.128-134.
Madden, A.D., 2022. A review of basic research tools without the confusing philosophy. Higher Education Research & Development, 41(5), pp.1633-1647.
Maher, C., Hadfield, M., Hutchings, M. and De Eyto, A., 2018. Ensuring rigor in qualitative data analysis: A design research approach to coding combining NVivo with traditional material methods. International journal of qualitative methods, 17(1), p.1609406918786362.
Ngo, T., Kunkel, J. and Ziegler, J., 2020, July. Exploring mental models for transparent and controllable recommender systems: a qualitative study. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization (pp. 183-191).
Nguyen, T.T., Maxwell Harper, F., Terveen, L. and Konstan, J.A., 2018. User personality and user satisfaction with recommender systems. Information Systems Frontiers, 20(6), pp.1173-1189.
Raghavendra, C.K., Srikantaiah, K.C. and Venugopal, K.R., 2018. Personalized Recommendation Systems (PRES): A Comprehensive Study and Research Issues. International Journal of Modern Education & Computer Science, 10(10).
Ramzan, B., Bajwa, I.S., Jamil, N., Amin, R.U., Ramzan, S., Mirza, F. and Sarwar, N., 2019. Intelligent data analysis for recommendation systems using machine learning. Scientific Programming, 2019.
Reddy, S.R.S., Nalluri, S., Kunisetti, S., Ashok, S. and Venkatesh, B., 2019. Content-based movie recommendation system using genre correlation. In Smart Intelligent Computing and Applications (pp. 391-397). Springer, Singapore.
Rezaeinia, S.M., Rahmani, R., Ghodsi, A. and Veisi, H., 2019. Sentiment analysis based on improved pre-trained word embeddings. Expert Systems with Applications, 117, pp.139-147.
Roy, S., Sharma, M. and Singh, S.K., 2019, October. Movie recommendation system using semi-supervised learning. In 2019 Global Conference for Advancement in Technology (GCAT) (pp. 1-5). IEEE.
Saraswat, M., Chakraverty, S. and Kala, A., 2020. Analyzing emotion-based movie recommender system using fuzzy emotion features. International Journal of Information Technology, 12(2), pp.467-472.
Singh, R., Singh, R. and Bhatia, A., 2018. Sentiment analysis using Machine Learning techniques to predict outbreaks and epidemics. Int. J. Adv. Sci. Res, 3(2), pp.19-24.
Singh, R.H., Maurya, S., Tripathi, T., Narula, T. and Srivastav, G., 2020. Movie recommendation system using cosine similarity and KNN. International Journal of Engineering and Advanced Technology, 9(5), pp.556-559.
Song, E.J., Lee, E.S. and Nam, Y.D., 2018. Progress of analytical tools and techniques for human gut microbiome research. Journal of Microbiology, 56(10), pp.693-705.
Thesing, T., Feldmann, C. and Burchardt, M., 2021. Agile versus waterfall project management: decision model for selecting the appropriate approach to a project. Procedia Computer Science, 181, pp.746-756.
Tweddle, J.F., Gubbins, M., and Scott, B.E., 2018. Should phytoplankton be a key consideration for marine management? Marine Policy, 97, pp.1-9.
Varghese, S.S., Ramesh, A. and Veeraiyan, D.N., 2019. Blended Module‐Based Teaching in Biostatistics and Research Methodology: A Retrospective Study with Postgraduate Dental Students. Journal of Dental Education, 83(4), pp.445-450.
Wang, H., Zhang, F., Wang, J., Zhao, M., Li, W., Xie, X. and Guo, M., 2018, October. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on information and Knowledge Management (pp. 417-426).
Wang, H., Zhang, F., Wang, J., Zhao, M., Li, W., Xie, X. and Guo, M., 2019. Exploring high-order user preference on the knowledge graph for recommender systems. ACM Transactions on Information Systems (TOIS), 37(3), pp.1-26.
Wu, C.S.M., Garg, D. and Bhandary, U., 2018, November. Movie recommendation system using collaborative filtering. In 2018 IEEE 9th International Conference on Software Engineering and Service Science (ACCESS) (pp. 11-15). IEEE.
Yao, Y. and Harper, F.M., 2018, September. Judging similarity: a user-centric study of related item recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems (pp. 288-296).
Zhou, K., Zhao, W.X., Bian, S., Zhou, Y., Wen, J.R. and Yu, J., 2020, August. Improving conversational recommender systems via knowledge graph-based semantic fusion. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 1006-1014).
Žukauskas, P., Vveinhardt, J. and Andriukaitienė, R., 2018. Philosophy and paradigm of scientific research. Management culture and corporate social responsibility, 121.
Go Through the Best and FREE Case Studies Written by Our Academic Experts!
Native Assignment Help. (2026). Retrieved from:
https://www.nativeassignmenthelp.co.uk/movie-recommendation-system-with-sentiment-analysis-case-study-18789
Native Assignment Help, (2026),
https://www.nativeassignmenthelp.co.uk/movie-recommendation-system-with-sentiment-analysis-case-study-18789
Native Assignment Help (2026) [Online]. Retrieved from:
https://www.nativeassignmenthelp.co.uk/movie-recommendation-system-with-sentiment-analysis-case-study-18789
Native Assignment Help. (Native Assignment Help, 2026)
https://www.nativeassignmenthelp.co.uk/movie-recommendation-system-with-sentiment-analysis-case-study-18789
- FreeDownload - 2106 TimesMeeting Consumer Needs Tesco And M&S Case Study
Introduction - Meeting Consumer Needs Tesco And M&S 1. Introduction...View or download
- FreeDownload - 1423 TimesBurj Khalifa Construction: Digital Technologies and Project Management Case Study
Burj Khalifa Construction: Digital Technologies and Project Management Enhance...View or download
- FreeDownload - 817 TimesPrimark: Analyzing Organizational Culture and Motivation Theories Case Study
Primark: Analyzing Organizational Culture and Motivation...View or download
- FreeDownload - 3548 TimesPerformance Optimization of a Racing Car Engine Using FEA Case Study
Chapter 1: Introduction 1.1 Introduction Improving the performance of vehicle...View or download
- FreeDownload - 939 TimesTheranos Leadership: Examining Corporate Ethics in Technology Startups Case Study
Risks and Failures of Entrepreneurial Deception in Silicon...View or download
- FreeDownload - 1042 TimesCase Study on Vulnerability Scanning and Security Reporting
Vulnerability Scanning and Reporting Second part: Vulnerability Scanning...View or download
-
100% Confidential
Your personal details and order information are kept completely private with our strict confidentiality policy.
-
On-Time Delivery
Receive your assignment exactly within the promised deadline—no delays, ever.
-
Native British Writers
Get your work crafted by highly-skilled native UK writers with strong academic expertise.
-
A+ Quality Assignments
We deliver top-notch, well-researched, and perfectly structured assignments to help you secure the highest grades.

